


When we work with a large amount of logs, sometimes millions or billions of events need to be parsed and queried to find the needle in the haystack. I’ve recently begun looking in to hooking an LLM to Elasticsearch to find indicators of compromise quicker. I plan on a model that works alongside the analyst which can be triggered during the start of an investigation and while manual review is taking place, the LLM bot can help derrive a similar or enhanced conclusion.
Disclaimer: This project uses 100% free and open source tools and is designed for plug and play with a Windows environment.
01 – Background
I’ve used a CSV > ELK uploader script which i’ve created and is in beta-testing now.
Link: https://dfirvault.com/csv2elk/
This is accompanied by another tool called ForensIQ which i developed and is in beta testing. This tool is a processor for log data either locally from CSVs or from Elasticsearch.
Link: https://dfirvault.com/forensiq/
The following diagram shows the relationship between the two tools.
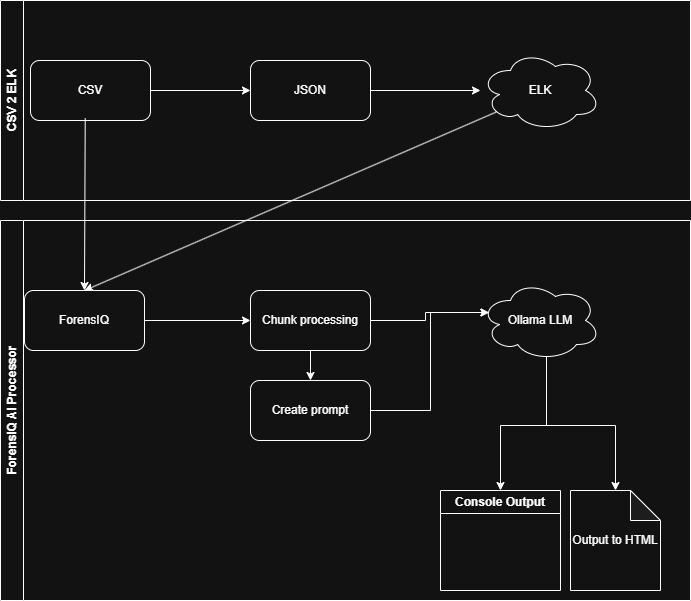
01 – Phase 1 – POC
The ForensIQ LLM parser will read in either lines from a CSV or entries from an Elasticsearch index and will split the source into chunks. An initial prompt is provided either default or custom from the user, which is then fed into each chunk that goes to the LLM. Additionally, any findings from analysis of previous chunks is provided in the prompt. This approach provides context of existing findings, provides a prompt for direction and the next set of logs to analyse.
Because this is running locally, we are restricted to physical limitations of the RAM, CPU and GPU for the amount of tokens that can be utilised in each chunk. Consider tokens to be a character limit for a prompt to the LLM service, if we send too many logs or too many words to the LLM, then the token limit will begin truncating additional data after that limit. This means we will loose many of the logs we are intending to investigate. So to get around this tokenisation limit, i’ve used a chunked processor method. The next phase of the project may look into expanding the token limit, but for now i’ve implemented a stable limit that self adusts based on the LLM used and includes error correction.
e.g.

Here is the output of phase 1 of the project



The following is an execution diagram that i’m working on:

02 – Phase 2 – Enhancements
In phase 1 i learned about token limitations in LLM’s. Basically we need to be considerate of the character limits that we send to our LLM service.
I’ve now implemented a selector which will read an external config file and will update that if any communication errors are identified. Additionally, it will read in the last-used model and will analyse the host system for the best LLM model for that computer. This will allow users to select an LLM model for detailed analysis, or a lightweight model if there is going to be a lot of logs expected.
Lastly, i have also implemented a function to save the console output to a html file.
The following is the output of the current phase, tested on mistral:

03 – Phase 3 – CSV support
I’ve now added CSV support so ForensIQ no longer needs to connect to an Elasticsearch endpoint. This may enabled a faster processing time during battlefield forensic situations where we need quick wins.
00 – How to run this project:
- Make sure you’re using Windows.
- Download Ollama: https://ollama.com/download/OllamaSetup.exe

- Install Ollama and make sure it’s running:
- To install the models in a different location than the software install directory, follow these steps:
- Open Windows Settings.
- Go to System.
- Select About
- Select Advanced System Settings.
- Go to the Advanced tab.
- Select Environment Variables….
- Click on New…
- And create a system variable called OLLAMA_MODELS pointing to where you want to store the models

- restart Ollama and confirm it is running by tray icon:

- Next, open a command prompt and type “ollama pull mistral”

- If you want to force GPU execution (recommended), run this command,
- setx “OLLAMA_GPU_ENABLED 1”
- set OLLAMA_GPU_ENABLED=1
- By default, ollama runs only through localhost, if you want to use a seperate compute server, then run the following:
set OLLAMA_HOST=0.0.0.0:11434
ollama serve - Next, double click the binary that is stored in the following repo: https://github.com/dfirvault/forensIQ
-

- Next, select either Elastcsearch service or Local CSV:

- From here, follow the prompts, it’s that simple.